
Итоги Trusted Media Challenge
Дипфейки — технологии создания реалистичных медиа с использованием глубокого обучения — все чаще применяются во благо: многие видели рекламу Сбера и Мегафона или слышали о переносе лиц актеров в кинематографе. Однако существуют опасения из-за применения таких алгоритмов с целью отъема денег у населения и создания дезинформирующих материалов. Результаты проведенного на 60 участниках исследования показали, что в 75% случаях люди не в состоянии распознать хорошую подделку, поэтому к детекции дипфейков приковано пристальное внимание разработчиков.
Целью обоих соревнований было создание ml-модели, максимизирующей точность предсказания, содержит ролик следы модификаций или нет. В Trusted Media Challenge некто Wang Weimin обошел 469 других команд со всего света с результатом 98,53%, однако это точность на данных из датасета, на котором обучались модели. Что будет на реальных данных с того же YouTube — большой вопрос (так, лучшая модель Deepfake Detection Challenge 2020 получила приличное падение с 82% до 65% при переходе с проверочных данных соревнования на реальные видео из сети).
Любопытно, что пресса уделила соревнованию большое внимание: два крупных азиатских новостных канала CNA и TheStraightTimes не только освещали проведение Trusted Media Challenge, но и выступили в качестве доноров, предоставив оригинальные (не фейковые) видео. Далее из них были получены фейки путем применения четырех методов замены лиц и двух методов замены голоса, при этом на оба канала накладывались дополнительные шумы (погодные эффекты, изменения яркости, эффект трясущейся камеры, изменение частоты голоса, аудиошумы).
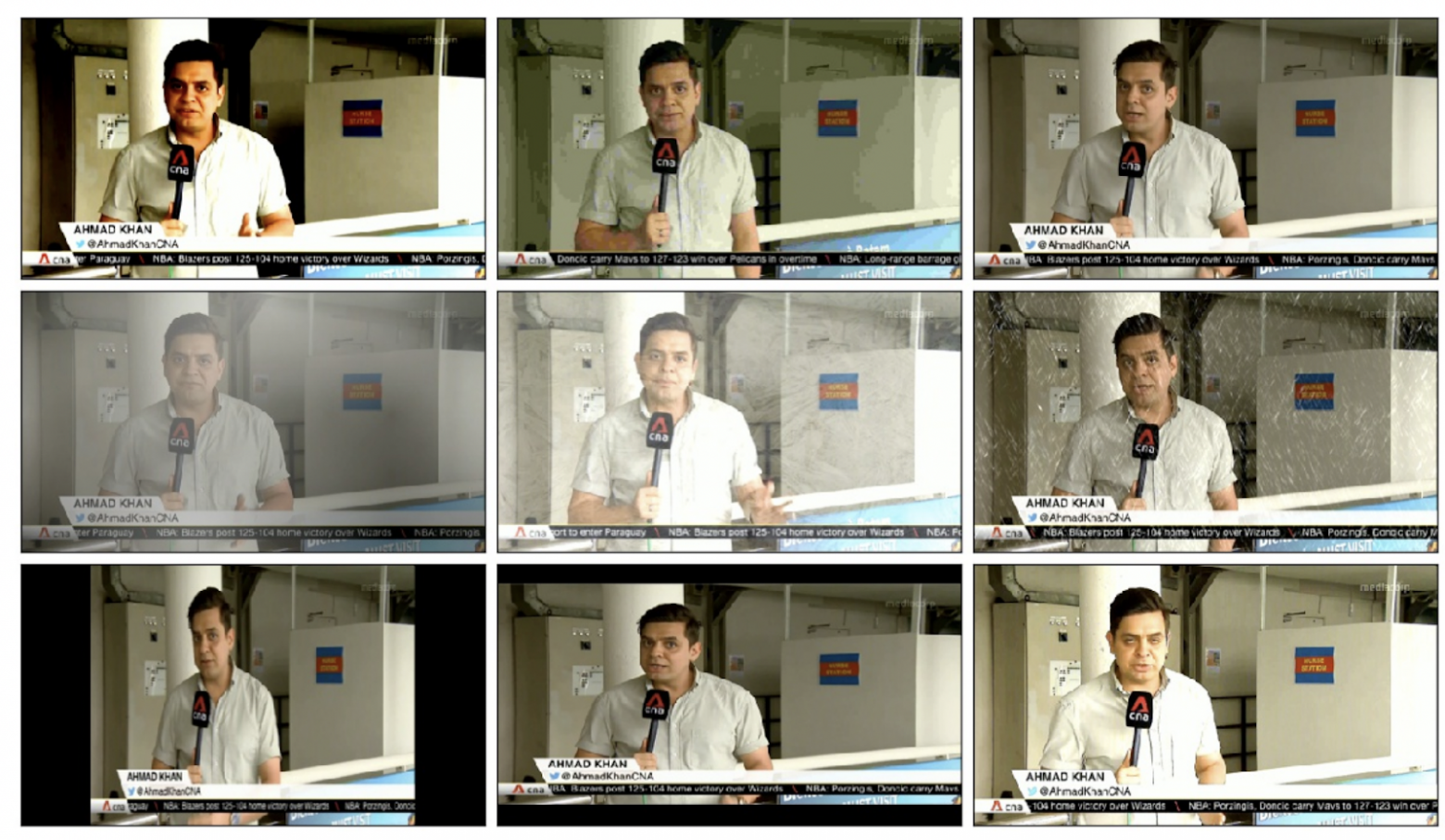
Все это в сочетании с разнообразностью датасета в контексте масштаба головы, разных углов поворота и разных уровней освещения позволяет надеяться, что победители соревнования смогли получить более устойчивые модели, которые можно будет применять в реальной жизни (пока только в азиатском регионе, поскольку в наборе данных наблюдается преобладание азиатских лиц).
Победитель Trusted Media Challenge работает в Bytedance (создатели Tiktok): он отказался от гранта и надеется на успешное внедрение алгоритма в рамках платформы BytePlus, предоставляющей разработанные компанией ml-алгоритмы на коммерческой основе. А может быть детекция появится непосредственно в Tiktok? В любом случае, как и с лицензированием медиа, дипфейкам и алгоритмам их детекции предстоит пройти долгий путь инкрементальных улучшений, прежде чем мы сможем выработать консенсус по их использованию.
Если вы хотите сами посмотреть, как справляются детекторы с разнообразными видео, не прибегая к запуску кода и поиску нужных чекпоинтов, в интернете уже существуют сервисы, которые могут сделать анализ в том числе с использованием модели победителя DFDC.
HeSeR: голова профессора Доуэля
Несмотря на обилие работ по улучшению методов замены лица с использованием deep learning, количество проектов по замене всей головы исчисляется единицами: ранее подобной возможностью могли похвастать лишь любимый многими DeepFaceLab, требующий большого количества ручной работы, а также StylePoseGAN, у которого наблюдаются проблемы с сохранением цвета кожи и бэкграунда.
Подавляющее большинство работ по замене лиц использует для контроля точности ту или иную предобученную нейросеть, однако все эти сети натренированы распознавать одну и ту же персону в разные годы жизни, в том числе с изменяющейся формой лица и разным прическами. Для полной замены головы они подходят плохо, вдобавок из-за головы другой формы в фоне могут появиться дыры, которые нужно будет закрасить.
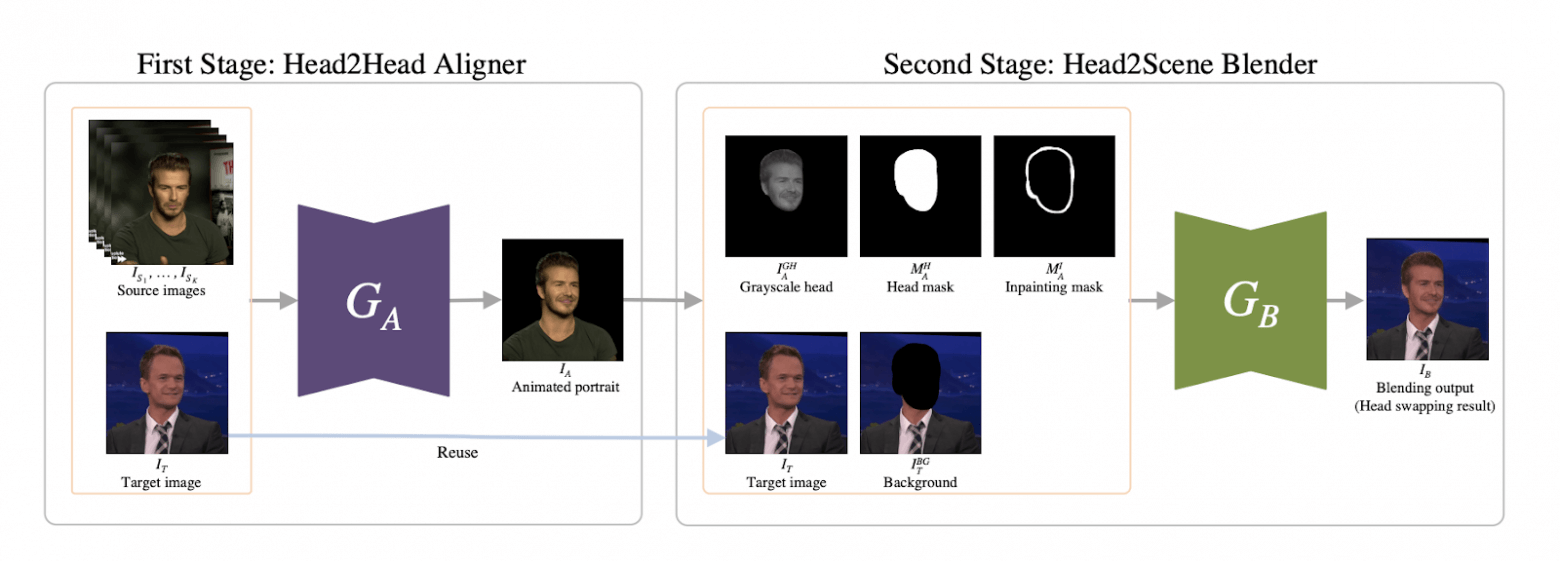
Справиться с проблемой авторы предлагают за счет использования двух отдельных блоков/нейросетей. Head2head aligner по сути решает задачу reenactment: генерирует изображение, в котором голова «донора» имеет позы и выражение лица, совпадающие с головой «реципиента», на тело которого будет происходить пересадка. При этом для улучшения результатов имеется возможность при создании каждого кадра использовать несколько разных ракурсов пересаживаемой персоны (чтобы восстанавливать те части, которых может быть не видно на одной фотографии). Чтобы лучше понять, как это выглядит на практике, стоит посетить сайты avatarify, pantomime или myheritage.
Head2scene blender вставляет по маскам reenacted-лицо с первого этапа в соответствующие кадры видео с соблюдением цветовой гаммы, при необходимости дорисовывая фон или убирая лишнее. Архитектурно это обычный Unet, а маски для вставки рассчитываются при помощи вспомогательной нейросети, которая умеет выделять части лица и фона (напишем так, потому что «отделение головы» звучит средневеково). Обучение этого всего балансируется достаточно сложной функцией потерь, содержащей большое количество компонент (для контроля сохранности позы, цветовой гаммы и т.д.), тут ничего нового.
Авторы обещают выложить код, но по традиции принятых на конференции (в данном случае речь о CVPR) статей, репозиторий пока что кода не содержит. И все же в предположении, что технология будет использоваться исключительно во благо, и что реальные результаты не хуже опубликованных в статье, хочется верить, что метод поможет более эффективно использовать дипфейки и нивелировать эффект зловещей долины. Попытки использовать замену лиц для улучшения diversity пока натыкаются на проблемы: результат из-за различия пропорций выглядит странно (эта сеть вполне может их решить).
Tortoise-tts: преобразование текста в речь, которая вам понравится
Подробное описание архитектуры доступно в блоге автора, однако стоит выделить основные принципы, которые поражают новаторством, особенно в контексте того, что все было сделано одним человеком (обычно схожие вещи делает условный DeepMind).
В основе лежит принцип, используемый в первом DALLE: одна модель генерирует кандидатов, а вторая отбирает самых подходящих. В качестве первой модели используется похожий на gpt2 трансформер-декодер, который на вход принимает преобразованные аудио и тексты, а на выходе последовательно один за одним генерирует набор токенов — последовательность сжатых аудио-представлений, соответствующих входному тексту. Стоит отметить, что все референсные аудио (фразы, принадлежащие человеку, которого мы хотим озвучить) преобразуются отдельным визуальным трансформером в векторы. Их усреднение дает латентный вектор, который несет нужную информацию о спикере (высоту и тон голоса, скорость речи и даже дефекты речи, вроде шепелявости или заикания). При этом этот визуальный трансформер создан по всем принципам современных эффективных визуальных трансформеров: аудио преобразуется в мел-спектрограмму, затем визуализированное аудио проходит через сверточные слои и только после этого подается на слои трансформера.
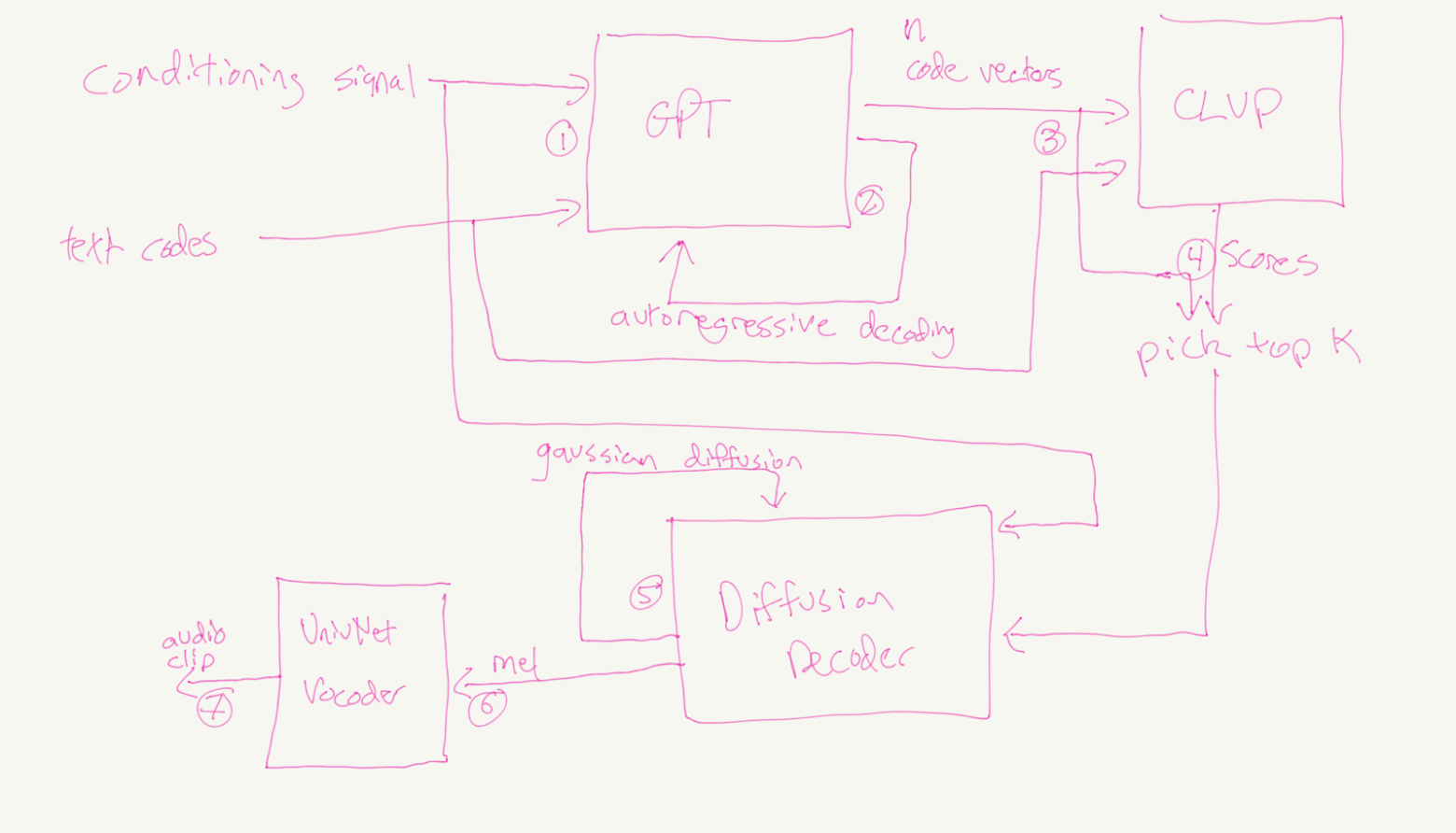 Для отбора самых подходящих выходов с декодера автор по аналогии с CLIP обучил две модели (CLVP и CVVP), которые позволяют оценить, насколько аудио-последовательности соответствуют тексту и латентному вектору (то есть конкретному спикеру). Отобранные последовательности аудио сжаты с большой потерей информации, поэтому прямое их декодирование в речь затруднено, так что далее в бой вступают еще две модели: диффузионный декодер выступает в роли модели super resolution для этих последовательностей и формирует мел-спектрограмму, а уже после этого предобученный вокодер (из популярных вариантов автором был выбран univnet из-за его легковесности и конкурентной производительности) генерирует речь.
Для генерации голоса нужной персоны достаточно взять некоторое количество примеров (автор утверждает, что достаточно 3 – 5 клипов по 10 секунд) и при помощи трансформера получить латентный вектор, который будет содержать все значимые характеристики. В случае генерации фраз на отличных от английского языках понадобится дополнительный сбор данных и переобучение отдельных компонент.
Дальнейшее развитие подобных проектов и отдельных архитектур из них способно существенно повысить влияние tts-технологий на общество, в том числе и в негативном ключе (достаточно подумать о возможных вариантах обмана по телефону). Автор в репозитории предлагает отдельную модель Tortoise-detect для детекции сгенерированных его моделью аудиозаписей, что опять же весьма инновационно и способно стать примером для других. А для любителей потестить все самим есть колаб.
Для отбора самых подходящих выходов с декодера автор по аналогии с CLIP обучил две модели (CLVP и CVVP), которые позволяют оценить, насколько аудио-последовательности соответствуют тексту и латентному вектору (то есть конкретному спикеру). Отобранные последовательности аудио сжаты с большой потерей информации, поэтому прямое их декодирование в речь затруднено, так что далее в бой вступают еще две модели: диффузионный декодер выступает в роли модели super resolution для этих последовательностей и формирует мел-спектрограмму, а уже после этого предобученный вокодер (из популярных вариантов автором был выбран univnet из-за его легковесности и конкурентной производительности) генерирует речь.
Для генерации голоса нужной персоны достаточно взять некоторое количество примеров (автор утверждает, что достаточно 3 – 5 клипов по 10 секунд) и при помощи трансформера получить латентный вектор, который будет содержать все значимые характеристики. В случае генерации фраз на отличных от английского языках понадобится дополнительный сбор данных и переобучение отдельных компонент.
Дальнейшее развитие подобных проектов и отдельных архитектур из них способно существенно повысить влияние tts-технологий на общество, в том числе и в негативном ключе (достаточно подумать о возможных вариантах обмана по телефону). Автор в репозитории предлагает отдельную модель Tortoise-detect для детекции сгенерированных его моделью аудиозаписей, что опять же весьма инновационно и способно стать примером для других. А для любителей потестить все самим есть колаб.